※ 학습자료 정리한 내용입니다.
16차시 머신러닝 개요 및 유형
Q. 용어 개념
- 머신러닝: '자동으로' 개선되는 컴퓨터 알고리즘에 대한 학문
- Artifical Intelligence ⊃ Machine Learning ⊃ Deep Learning (가장 유명한 알고리즘)
Machine Learning 종류 **
| Machine Learning | ||
| Supervised Learning | Unsupervised Learning | Reinforcement Learning |
| Task Driven ( Regression / Classification) | Data Driven (Clustering / 차원축소) | Algorithm learns form mistakes |
[Supervised Learning, 지도학습]
= '교사학습', Deep Learning
- 입력값과 출력값이 함께 제시됨. 정답을 들고 있음
- 알고리즘은 입력값과 출력값 사이의 관계를 가장 잘 설명할 수 있는 '모델'을 찾음 -> 새로운 입력값에 대한 예측 수행
- 출력값이 수치형인 회귀와 범주형인 분류 문제로 나누어 짐
Q. 데이터셋 feature(열)을 보고 이 문제를 풀기 위한 알맞은 알고리즘은?
A. 지도학습의 알고리즘 종류를 보기로 줌
[Unsupervised Learning, 비지도학습]
= '자율학습'
- 우리가 가진 데이터셋 안에 출력 값이 없음. 정답이 없음
- 적절한 군집을 찾거나, 변수의 복잡성을 낮추기 위한 차원 축소 등이 포함
Q. 지도학습 vs 비지도학습
[Reinforcement Learning, 강화학습]
- 구체적인 행동에 대한 지시가 없이 목표만 주어짐
- 현재 상태에 대한 최선의 액션을 보상에 의해 스스로 찾아 학습하게 하는 방법-> 최고의 결과를 얻기 위한 전략으로 활용
- 'Agent', 'Reward'
[그 외, Semi-supervised Learning]
- 모든 데이터에 항상 레이블을 달아 줄 수 있는 것이 아닌 현실을 고려한 접근법
- 레이블 O , 레이블 X 데이터를 동시에 사용하여 더 좋은 모델을 만들고자 함
- 항상 최선의 성능이 발휘되는 것은 아니나, 군집형태에 가까운 경우 좋은 결과를 나타냄
ex) Unsupervised Learning , 데이터가 총 4가지 군집으로 묶음 (가장 좋은 성능)
-> 이 결과로 -> Supervised Learning , 4가지 군집에 각 target(결과) 값을 줌
[그 외, Transfer Learning]
- 기존에 학습된 모델을 이용하여 미세 조정하여 사용하는, 새로운 모델을 만드는 방법
- 해결하고자 하는 문제가 유사성이 있을 경우, 학습 데이터가 부족한 경우 등에 사용
Machine Learning W/F
1. Collect data: 유용한 데이터를 최대한 많이 확보하고 하나의 데이터 세트로 통합
2. Prepare data: 결측값, 이상값, 기타 데이터 문제를 적절하게 처리 -> 사용가능한 상태로 준비 '데이터클리닝/전처리'
? sampling 방법은 적절한가? 전체 데이터를 잘 표현하는지?
3. Split data: 학습용 set (검증용 set), 평가용 set (검증용 set)로 데이터 분리
? 적절한 테스트를 위한 데이터 분할 방법은?
4. Train a model: 이력 데이터의 일부를 활용하여 알고리즘이 데이터 내의 패턴을 잘 찾아주는지 확인
? 어떤 모델/ 어떤 변수를 사용하지?
5. Test and validate a model: 학습 후 모델의 성능을 평가용 데이터 세트로 확인하여 예측 성능을 파악
? 충분한 예측력을 가진 모델인가?
6. Deploy a model: 모델을 의사결정 시스템에 탑재/적용
7. Iterate: 새로운 데이터를 확보하고 점증적으로 모델을 개선
~ ( 반복 )
Q. W/F 묻는 문제는 나오지 않으나, 데이터분석프로세스에 대한 이해가 되어야 실기가 수월함
1 단계: 데이터 결합
2 단계: 데이터 전처리 - 결측값, 이상값, 탐지 및 처리
3 단계: training - test data로 데이터 분리
4 단계: training data로 모델 생성 -> test data를 생성한 모델에 넣어 성능 확인
Bootstrap 부트스트랩
- 복원 추출을 허용하는 단순 임의 표본추출로, 학습 데이터의 크기를 늘리는 효과 기대
- 데이터(특히 종속변수) 불균형(imbalanced data)인 경우에 대한 보완 방법
불균형(imbalanced data): 종속변수가 범주형 데이터 일 때, 범주 별로 관측치의 개수, 비율의 차이가 많이 나는 데이터
- 분류모델의 경우, 종속변수 범주의 구성비가 서로 같은 경우 일반적으로 성능이 가장 좋음.
서로 다른 경우 모델의 성능이 좋지 않음.
알고리즘을 모르면 데이터 전처리를 못 함!
어떤 알고리즘을 쓰느냐에 따라 데이터 전처리 방법이 달라짐
17차시 특성공학1_Under/Over fitting ****
Feature Engineering, 특성공학
[개념]
- 좋은 예측 결과를 얻을 수 있는 특징(feature) 찾기
- feature : 데이터셋의 column 정보,
대상 문제에 유용/의미 있는 특징,
Feature의 중요도를 객관적으로 측정할 수 있고, 그 크기에 따라 모델에 포함하거나 제외할 수 있음
[중요한 이유?] 단순한 모델로 좋은 성능을 낼 수 있음
- more flexibility: 좋은 feature들을 찾게 되면 복잡하지 않은 좋은 성능 기대-> 비용 감소
- simpler models: 단순한 모델을 갖고 일을 할 수 있음
- better results: 좋은 데이터에 대해 좋은 결과 기대
[어떤 feature가 중요한 가?] 데이터의 중요도를 측정할 수 있는 개념
- 상관계수: 데이터 간의 선형성
- 회귀계수: 기울기, 절편을 통해 인과관계
- p-value: 유의 수준 알파벳보다 큰지, 작은 지에 따라 귀무가설을 계약할지 결
- 의사결정 나무의 Feature Importance:
-> 모델로, 예측 분류/ 회귀문제 풀 수 있음
[방법]
특징 추출, Feature Construction: Raw Data로부터 새로운 Feature를 만들어내는 경우
- "수작업"으로 이루어지며 매우 느리게 진행
- Feature Extraction: 특징추출, 원래 있는 데이터를 바꿔주며 새로운 데이터를 만들어내는 경우 "자동화"
- Feature Learning : Raw Data로부터 새로운 Feature를 만들어내는 경우
1) 비지도 학습, 세미지도 학습 등의 방법으로 feature에 대한 학습을 통하여 featrue의 적절한 구성, 선택을 자동을 지원
특징 선택, Feature Selection: Feature 가 많은 경우
- Feature 중요도 점수를 다양하게 분석하고 선택
Q. Feature Extraction vs Feature Construction vs Feature Learning
A. 공통점: 새로운 데이터를 만드는 경우
차이점: Extraction는 자동화의 개념. Construction는 수작업의 개념. Learning 은 비지도 학습
[Feature Engineering Process in Machine Learning]
| Select Data | ||||
| Preprocess Data | ||||
| Featrue Engineering 필요한 단계 | Transform Data | -> Brainstorm Feature 데이터분석, 다른 사례 검토 | -> Devise Feature 자동 혹은 수동 수행 (Extraction or Construction) | -> Select Feature Feature 중요도 점수 분석, 선택 |
| Model Data |
- Feature Extraction or Construction 수행한 후, Select Feature 진행됨
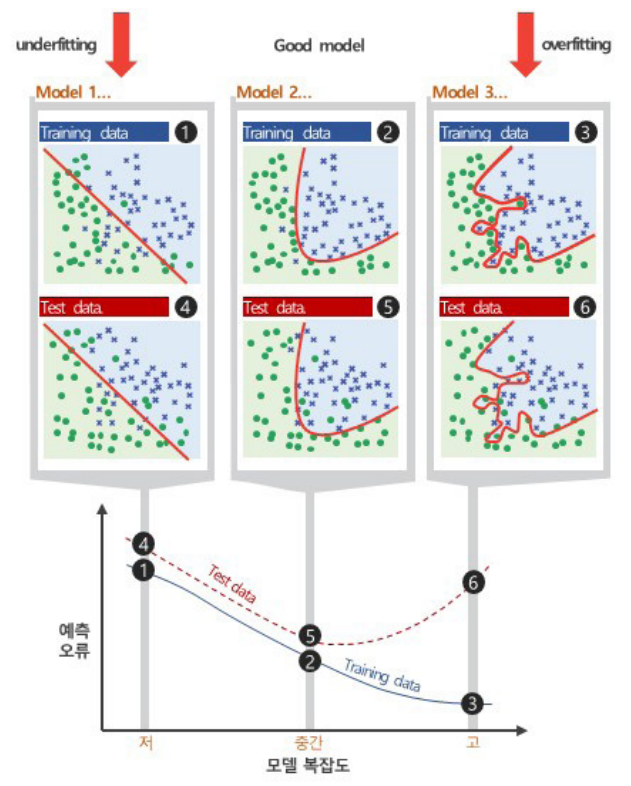
Underfitting / Overfitting
[Machine Learning의 목표는 '일반적인 패턴' or '모델'을 찾는 것]
- 전수에 가까운 조사가 가능하다면 최선
- 항상 Sample data 만의 특징이 존재할 수 있고, 이 모델은 새로운 데이터를 잘 설명하지 못하는 상황이 발생할 수 있음
- 지나치게 단순한 모델은 새로운 데이터도 충분히 설명하지 못하는 상황이 발생
기본 데이터를 training data와 test data로 split 한 후, 발생할 수 있는 오류는?
보통은 training data로 모델을 만들고 test data로 모델을 성능 평가(예측)한다.
[학습 오류, 일반화 오류 그리고 예측 오류]
- 학습 오류: 학습 데이터를 사용하여 모델을 생성하고 측정한 오류
- 일반화 오류: 기본 데이터 분포에서 새로운 데이터를 추출, 모델에 적용할 때 예상되는 오류. 사실 잘 알 수 없음
- 예측 오류: 테스트 데이터를 모델에 적용하여 측정한 오류로, 일반화 오류의 추정에 사용
머신러닝은 학습오류와 일반화 오류 사이의 격차를 최소화하는 것이 목표! (사실 이 방법이 어렵기 때문에, 다음)
일반화 오류는 예측 오류로 추정함!
[편향(Bias) , 분산(Variance)]
- 편향: 예측값이 정답과 얼마나 다른가?
- 분산: 예측값이 서로 얼마나 흩어져 있는 가?
데이터 안에 있는 에러, 노이즈들이 모델을 만들어갈 때 영향을 끼친다
특정 입력 데이터에 대해 알고리즘이 얼마나 민감한 지를 나타냄
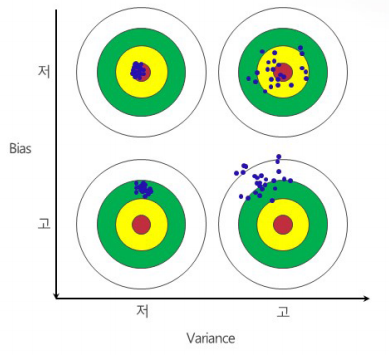
[모델의 복잡도]
- 입력 변수가 증가하면 모델 복잡도 증가
ex) A+Bx < A+ Bx1 + Cx2
- 출력 변수의 가능한 class 가 늘어나면 모델 복잡도 증가
ex) black, white < black, blue, green, red,,,
- 두 변수가 비선형관계이면 모델 복잡도 증가
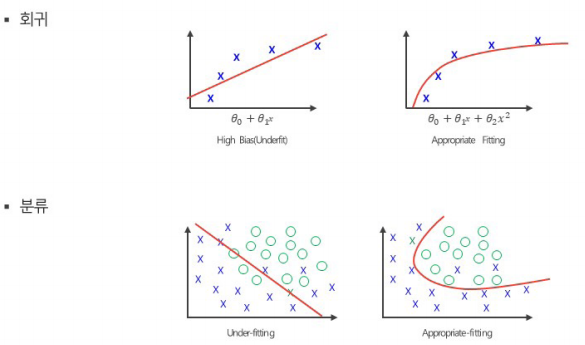
[Underfitting, 과소적합]
- 주어진 입력 데이터에 비하여 모델 복잡도가 너무 낮아, 입력 데이터로부터 충분히 학습하지 못하는 상황
- 너무 모델이 단순해서 성능이 떨어짐
- 대응 방법
1) (모든 경우는 X) 딥러닝이나 Auto-parameter Tuning인 경우, 학습시간을 늘린다
2) 더 복잡한 모델을 구성
3) 모델에 추가 Feature를 도입
4) Regularization을 사용하지 않거나 영향을 줄임 - ( Regularization은 overfitting의 개념)
5) 모델을 다시 구축
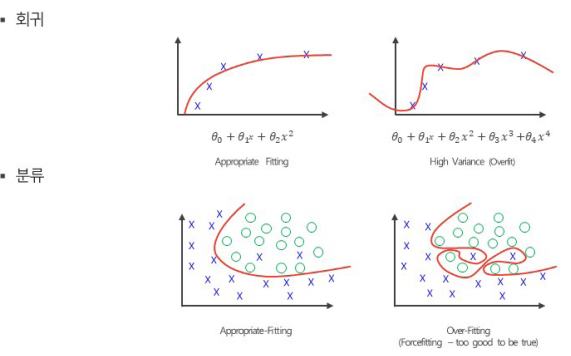
[Overfitting, 과(대) 적합]]
- 모델 복잡도가 너무 높아 입력 데이터의 잡음까지 fitting 하는 경향을 보임 -> 일반화 실패
- 너무 다 맞추려고 함
- 대응 방법
1) 학습을 더 일찍 멈춤
2) 데이터를 추가: 특정 데이터에 편향되지 않게
3) 모델의 복잡도를 낮춤
4) 일부 Feature을 제거: 너무 복잡하지 않게
5) Regularization을 활용: 규칙화 정규화, 너무 잘 맞추지 않게 성능을 떨어트려 일반화 시킴
6) 앙상블 모델을 적용: 여러 가지 알고리즘을 같이 사용한 모델
18차시 특성공학 2_모델평가기법
- 모델 분리하고 검증하는 방법을 배워보자
Data Split과 모델 검증
WHEN?
- "충분히 큰" 데이터 세트가 가용할 때
- '충분히 큰' 기준은 알고리즘, 분석마다 다름
- '충분히 큰' 데이터가 없을 때는 교차 검증(cross validation)을 고려
WHY?
- 학습에 사용되지 않은 데이터를 사용하여 예측을 수행함으로써 모델의 일반적인 성능에 대한 적절한 예측을 함
training, test data로 나누고, training data로 만든 model에 대해서 test data로 성능을 평가받게 되는데
이때, model 은 항상 새로운 data를 통해서 (training data가 아닌) 성능 평가가 된다. = 일반적인 성능 평가
HOW?
- Hold-out: training data 1개, test data 1개로 split
- Cross validation: 위의 개념을 여러 번
[ Hold-out ]
-
[ Cross validation ]
- k-fold Cross validation ( k = 10)
-
일반적인 모델 선택 과정
1. 여러 모델을 대상으로 교차검증(Cross validation)을 수행
2. 가장 좋은 결과를 낳은 모델을 선택 (1개 or 다수)
3. 학습 training 데이터를 모두 사용하여 모델 생성
4. 평가 test 데이터로 모델 예측, 평가
모델 평가는 어떻게 하는 가?
평가 지표
- 회귀 모델: 예측 대상(target) 이 연속형 수치 데이터인 경우
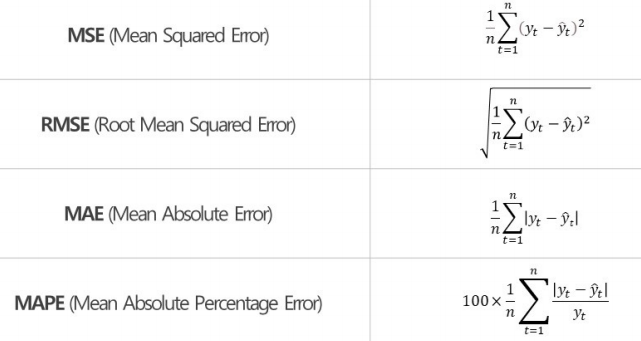
- 분류 모델: 예측 대상이 범주형(문자) 데이터인 경우. Yes or No
Confusion matrix를 그려야 함 ** 문제 최소 1개
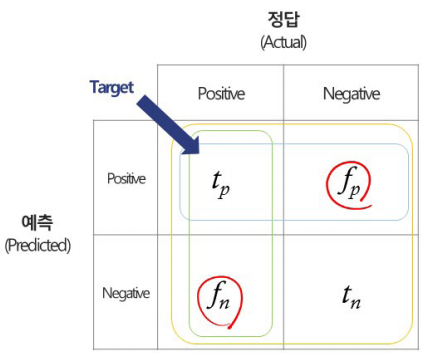
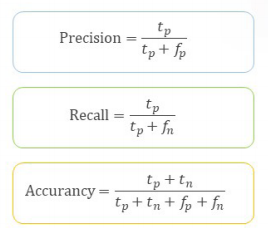
- Accurancy(정확도): 전체 중에 예측이 맞은 것
-> 현업에서 잘 사용되지 않음
- Precision(정확률): 행 정보(positive 예측 전체) 중에 실제 예측이 맞은 것
-> 내가 만든 모델의 정확도. 값이 클수록 좋음
- Recall(재현율): 열 정보(실제 positive 전체) 중에 실제 예측이 맞은 것
-> 내가 만든 모델을 사용하면 어느 정도 재현 가능. 값이 클수록 좋음
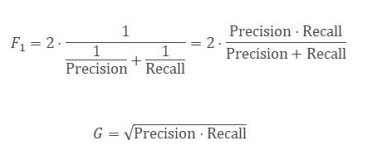
평가지표 Precision, Recall 값이 크지만 서로 다른 경우에는?
하나의 평가지표를 사용하고 싶을 때 F1 score (= measure)를 사용
Q. F1 오른쪽 수식 외우기
- 오분류 행위를 비용으로 측정
Total Cost = c(FP) * FP + c(FN) * FN
FP: False Positive, FN: False Nagative, c(): 관련비용
Q. 시험에서는 c() 가 주어질 거고, FP,FN만 계산
모델 선택 및 평가 **
- 모델 평가에 가장 널리 사용되는 지표는 예측력
1) 회귀 모델의 평가에는 오차의 크기
2) 분류 모델의 평가에는 정확도 개념 사용
- 예측력이 유일한 지표는 아니며, 지표들이 독립적이지 않으므로 입체적인 고려가 필요
1) 해석력: 입력과 출력 간의 관계를 잘 설명하는 가?
2) 효율성: 유사한 성능을 보이는 경우, 적은 입력 변수로 모델을 구축하는 가?
3) 안정성: 새로운 데이터 세트에도 같은 성능의 결과를 나타내는 가?
'Data Science > 이론' 카테고리의 다른 글
| DS 이론 21- KNN 알고리즘 (0) | 2024.12.08 |
|---|---|
| DS 이론19~20- 선형회귀분석(머신러닝),로지스틱 회귀분석* (0) | 2024.12.03 |
| DS 이론13~15-데이터 전처리(결측치, 정규화, 변환) (0) | 2024.11.23 |
| DS 이론 11-선형회귀분석3_이슈처리,성능평가지표,명목형변수 (0) | 2024.11.22 |
| DS 이론10-선형회귀분석2_통계파트(주요 가정) (1) | 2024.11.22 |