9차시 데이터 전처리: 정렬 및 변환
정렬
- 특정 변수의 최대값, 최소값을 확인할 때 사용
- 시간 순서대로 데이터를 정렬할 때 활용
Pandas - crosstab( ) 교차분석(cross tabulations)
: 범주형 변수로 되어있는 요인별로 교차분석(cross tabulations) 해서,
행, 열 요인 기준 별로 빈도를 세어서 도수분포표, 교차표 를 만들어줌 (명목척도 - 교차분석)
- 데이터프레임의 두 변수의 원소 조합 빈도를 확인하는 함수
- normalize 설정으로 각 조합의 비율을 계산 = 정규화
Q. workingday 가 아니면서 holiday가 아닌 날의 비율은?
- value , aggfunc 설정하면 빈도가 아닌 별도 산술연산 가능 -> groupby 와 유사한 기능도 있음
(3) crosstab 결과에 대한 분석
(1) sum( 특정변수 조건 & 조건) = (2) .loc 에 대한 결과 갯수 len




정규화 normalize
normalize : bool, {'all', 'index', 'columns'}, or {0,1}, default False
Normalize by dividing all values by the sum of values.
- If passed 'all' or `True`, will normalize over all values.
- If passed 'index' will normalize over each row.
- If passed 'columns' will normalize over each column.
- If margins is `True`, will also normalize margin values.
- 축 방향 지정
normalize = 0 은 가로(row) 총 합이 1이다. ex) ['cut']이 Fair 인데, ['clarity'] IF 의 비율
normalize = 1 은 세로(column)가 총 합이 1이다. ex) ['clarity'] IF 인데, ['cut']이 Fair 의 비율
- 소수점 : .round(n)
- 백분율 : *100


value , aggfunc 설정하면 빈도가 아닌 별도 산술연산 가능 -> groupby 와 유사한 기능도 있음
- cut 별 clarity에 대한 price 의 평균 = groupby -> 자료 결과 모양이 다를 뿐, 결과는 같음!

value , aggfunc 좀 더 쉬운 예제

- data.fac_2 == 'c' & data.fac_1 == 'a' -> 겹치는 게 없으니, sum 해도 NaN임. 따라서, 결측치 처리하여 0.
- data.fac_2 == 'd' 중 data.fac_1 == 'd' 인 것은 'id1' 3개가 있음. sum을 하여 'id1id1id1' 으로 리턴됨.
Pandas - sort_values( )
- 특정 변수를 기준으로 정렬하는 메서드. 어떤 변수는 오름/ 다른 변수는 내림차순으로 설정 가
- ascending 설정으로 오름차순/ 내림차순 설정 가능
- 두 변수 이상의 기준으로 정렬 시 리스트 형식으로 각 인자에 값 할당

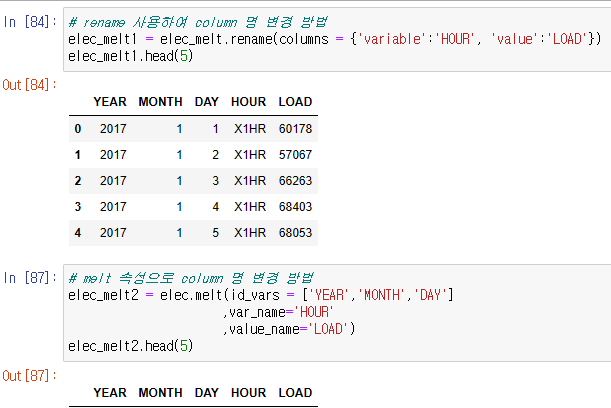
Pandas -melt( )
- wide form -> long form Dataframe으로 자료구조를 변환하는 메서드
- id_vars 인자에 기준이 되는 변수를 지정하여 처리
- 통계, 머신러닝 실시 전에 데이터 구조를 맞추기 위해 주로 활용


Pandas -pivot( ) 피벗
- long form -> wide form 으로 변환
- index/ columns/ values 인자에 대상 변수를 지정하여 출력 데이터 구조 결정
- 데이터 요약, 군집분석 실시 전 데이터 전처리에 활용

( 반복 ! )
Q. workingday 가 아니면서 holiday가 아닌 날의 비율은? *bike.csv
pd.crosstab(bike['workingday'], bike['holiday'], normalize=True).round(2)
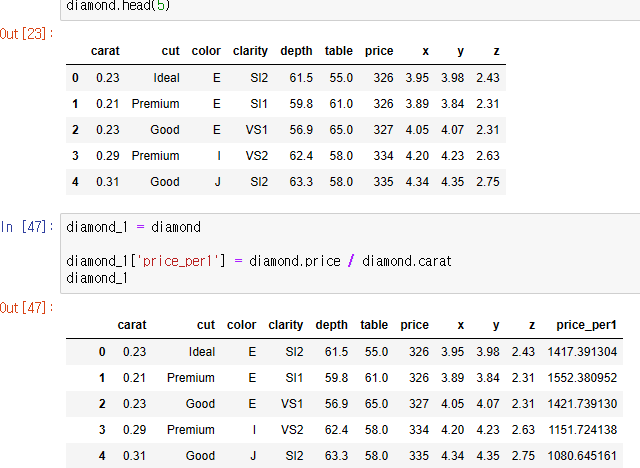
Q. 가장 많은 데이터가 있는 세공 수준과 색상 조합을 순서대로 고르면? *diamonds.csv


Q. 세공(cut) 수준별 색상별 1캐럿당 가격의 평균을 구하고, 1캐럿당 가격이 가장 높은 세공수준과 색상 조합을 순서대로 고르면? *diamonds.csv

10차시 데이터 전처리: 사용자 정의 함수 활용
def #함수명(#인자):
#실행 코드
return #반환값
- 시험에 잘 나오지는 않을 듯


'Data Science > 실습' 카테고리의 다른 글
| DS 실습 12- 비계층적 군집분석(KMeans,MinMaxScaler,StandardScaler,shilhouette_score) (1) | 2024.12.06 |
|---|---|
| DS 실습 11- 상관분석(Pandas.corr, scipy) (0) | 2024.12.05 |
| DS 실습6~8- 데이터전처리(결측치,이상치,파생변수,데이터병합) (0) | 2024.11.24 |
| DS 실습5- 표본 추출(sample, random_state, train_test_split) (0) | 2024.11.23 |
| DS 실습4- Numpy, pandas(Series,DataFrame)* (2) | 2024.11.22 |