이론) 2024.11.23 - [공부는해야지/data science] - DS 이론 10-데이터 전처리1_데이터크리닝
6차시 데이터 전처리: 결측치, 이상치
[이상치]
- 중심 경향성에서 멀리 떨어진 값
- 처리방법
1. 이상치 처리에 절대적인 기준은 없음
2. Carling, Tukey 방법
3. 분포 기반으로 처리
[결측치]
-값이 기록되지 않고 비어있음
-처리방법
1. 결측치 처리에 절대적인 기준은 없음
2. 단순 제거와 특정 값으로 대체
3. 분석 데이터에서 결측치가 차지하는 비중이 낮은 경우, 단순 제거하는 경우가 많음

pandas - isna(), isnull()
- 결측치 원소를 True, 관측치를 False로 변환하는 메서드
- isna(), isnull() 동일 함수이며, isnull 은 isna의 Alias name이다. 아래는 isnull의 설명 중 일부.
DataFrame.isnull : Alias of isna.
- 반대기능: notna(), notnull()



pandas - fillna()
- 결측치를 채워 넣기 위한 메서드
- value 인자에 결측치를 채워 넣을 값을 입력하여 딕셔너리 사용 가능
- 주의) df_na.fillna(value = 999) 하는 경우, 모든 결측치에 999 값으로 채워지는 데 기존 데이터타입과 상관없이 들어가기 때문에 확인 필요.


- 결측치 처리 방법 中 평균값 사용
: 지정한 column에 평균값으로 결측치 처리된 것을 볼 수 있다.

- method에 'bfill'은 뒤의 값을, 'ffill'은 앞의 값을 참고하여 결측 처리
주의) bfill의 경우, 마지막 값은 뒤의 값이 없기 때문에 NaN 유지되는 것

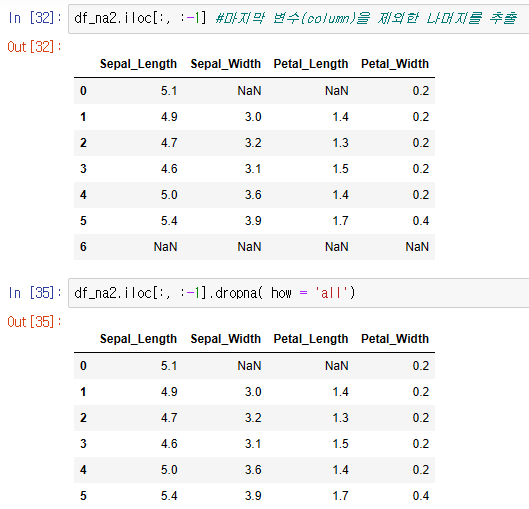
pandas - dropna()
- 결측치가 있는 row / column을 제거하기 위한 메서드
- how 인자에 'any'는 결측치가 하나라도 있는 경우, 'all'은 전체가 결측인 경우 제거
how : {'any', 'all'}, default 'any'
Determine if row or column is removed from DataFrame, when we have
at least one NA or all NA.
* 'any' : If any NA values are present, drop that row or column.
* 'all' : If all values are NA, drop that row or column.

pandas - quantile()
- 분위수를 연산하는 메서드로 이상치 필터링에 활용
- q인자에 1개 이상의 확률(0~1)을 입력하여 그에 맞는 분위수 산출 가능
df_na2["Sepal_Length"].quantile(q = 0.25) # 제 1분위수
df_na2["Sepal_Length"].quantile(q = 0.5) # 제 2분위수
df_na2["Sepal_Length"].quantile(q = 0.75) # 제 3분위수
*정답(추출식)은 아래 부분을 드래그하세요
Q. 각 수치형 변수의 결측치 개수 총합은?
- 추출식
df.iloc[:,:-1].isnull().sum().sum()
Q. sepal_width 변수의 결측치를 평균으로 대치한 값의 분산은?
- 추출식
df = df.fillna(value = {"Sepal_Width" : df["Sepal_Width"].mean()})
df["Sepal_Width"].var()
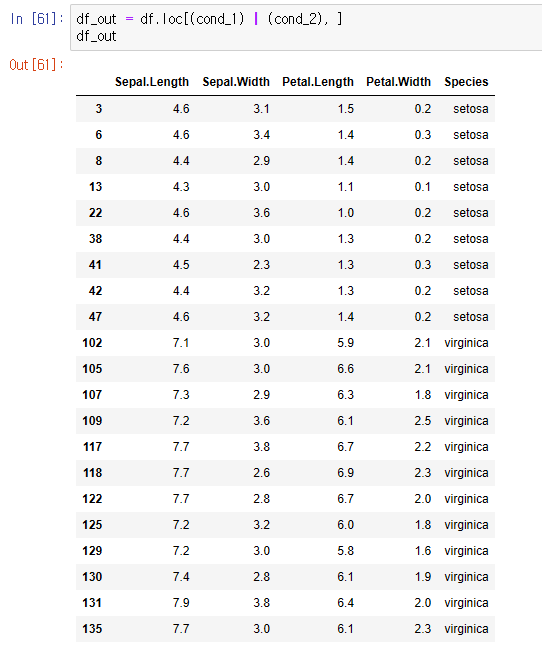
Q. 평균을 기준으로 1.5 표준편차를 넘어서는 값을 이상치라고 간주할 때 Sepal.Length 변수를 기준으로 이상치인 row 개수는 몇 개인가?
- 추출식 *어렵
sl_mean = df["Sepal.Length"].mean()
sl_std = df["Sepal.Length"].std()
cond_1 = df["Sepal.Length"] < (sl_mean - 1.5 * sl_std)
cond_2 = df["Sepal.Length"] > (sl_mean + 1.5 * sl_std)
df_out = df.loc[(cond_1) | (cond_2), ]
len(df_out)

7차시 데이터 전처리: 파생변수 생성
[파생변수]
- 기존 변수를 조합하여 만들어내는 새로운 변수
ex)
기온+습도+풍속 -> 체감온도 변수
물건 주문건수+환불건수 -> 환불비율 변수
기존 방문매장정보를 활용한 주 방문 매장 변수
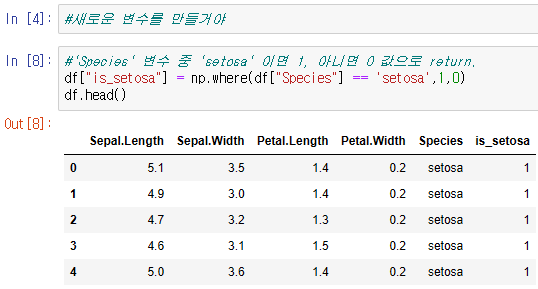
numpy - where()
- 조건에 따라 두 개의 출력을 내는 함수
- if () 함수를 대체할 수 있으며 조건 True 반환값, False 반환값을 차례대로 기입
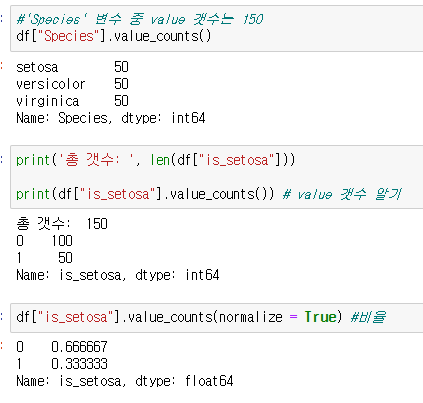
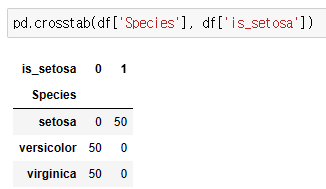
- pandas.crosstabe 사용하여 데이터 확인
: 'Species'변수 중 'setosa' 이면 1, 아니면 0으로 새로운 변수 'is_setosa'의 데이터 확인
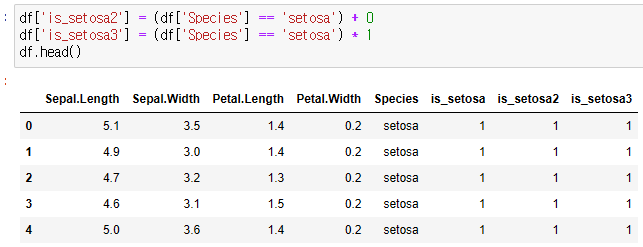
- 간단한 수식이라면 numpy.where 사용하지 않고, True/ False 성질을 이용하여 간단하게 사용 가능
pandas - rename()
- 데이터프레임의 변수명을 변경할 때 사용하는 메서드
- columns 인자에 기존 변수명과 신규 변수명의 쌍을 딕셔너리로 구성하여 입력
#꼭 원본에 덮어써야 적용됨
df = df.rename( columns = {'Sepal.Length' : "SL"})
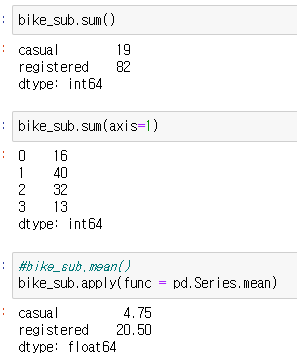
pandas - apply()
- row, column 방향으로 일괄 계산하는 메서드
- axis 인자 설정으로 연산 방향 설정 가능 (axis = 0은 row, axis = 1은 column 방향)
- 사용자 정의 함수 또는 lambda 함수(일회성 함수)로 복잡한 연산 가능
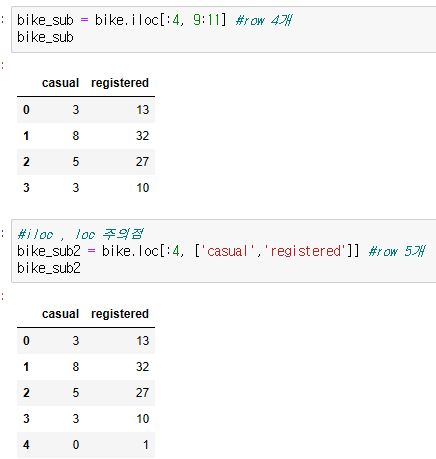
.iloc / loc 주의
- .iloc : interger location의 뜻. 정수로 위치 접근/ row 슬라이싱할 때, [ :n] 은 n 이전까지
- .loc : column 명을 직접 지정하여 접근 / row 슬라이싱할 때, [ :n] 은 n까지
pandas - astype()
- 시리즈의 속성을 변경할 때 사용하는 메서드
- int/ float/ str 은 각각 정수/실수/문자열을 뜻하며 원하는 속성을 지정 및 변경
시간 type
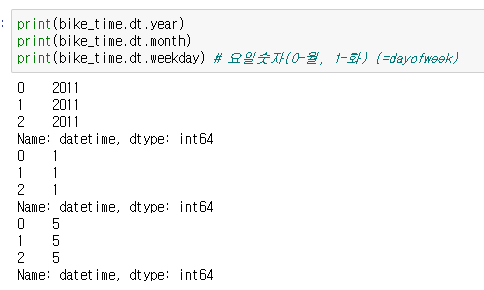
- 문자열인 것을 날짜형식으로 변경하여 원하는 부분만 추출할 수 있음
pd.to_datetime()
.dt.year

pandas - get_dummies()
- 편리한 가변수 생성(One Hot Encoding)을 도와주는 함수
- columns 인자에 명목형 변수 지정 및 처리 가능 ( 반드시 리스트로 할당)
- drop_first 인자에 True를 입력하면 마지막 가변수 제외 후 생성
이론) 2024.11.22 - [공부는해야지/data science] - 통계분석 요약 8-선형회귀분석3_이슈처리,성능평가지표,명목형변수
8차시 데이터 전처리: 데이터 병합
병합의 종류
- 데이터를 이어 붙이는 바인딩(Binding)은 행/ 열 방향으로 연산 가능
- 특정 변수를 기준으로 두 데이터를 엮는 Join을 많이 사용
- Inner Join : key 변수가 공통인 행을 반환
- Left Join : A세트의 모든 행을 유지하고 B세트는 key 변수 기준으로 공통인 행을 반환
pandas - reset_index()
기존의 인덱스를 초기화하는 메서드
dataFrame의 인덱스를 초기화할 경우, 0부터 row 개수만큼의 숫자가 재할당
사용방법)
1. 필터링/ 정렬하고 나서 초기화하는 경우 사용
2. groupby() 연산 등으로 특정한 기준 변수 내용이 index로 들어가 있는 경우, 데이터프레임으로 정리하기 위해 사용
pandas - set_index()
특정 변수를 인덱스로 지정할 경우 사용하는 메서드
데이터 병합 또는 시계열 분해에서 연산을 위해 활용
ex)

'Data Science > 실습' 카테고리의 다른 글
| DS 실습 11- 상관분석(Pandas.corr, scipy) (0) | 2024.12.05 |
|---|---|
| DS 실습9~10-데이터전처리(정렬 및 변환-crosstab, sort_values, melt/ def) (0) | 2024.12.01 |
| DS 실습5- 표본 추출(sample, random_state, train_test_split) (0) | 2024.11.23 |
| DS 실습4- Numpy, pandas(Series,DataFrame)* (2) | 2024.11.22 |
| DS 실습1~3- Python 기본문법 (0) | 2024.11.22 |