2024.12.08 - [Data Science/이론] - DS 이론 22- 나이브베이즈분류, 예제
DS 이론 22- 나이브베이즈분류, 예제
https://sometipsfor.tistory.com/39 DS 실습 16- 나이브 베이즈- 사전 확률 및 추가 정보를 기반으로 사후 확률을 추론하는 통계적 방법인 베이즈 추정 기반 분류- 종속변수 각 범주의 등장 빈도인 사전확
sometipsfor.tistory.com
- 사전 확률 및 추가 정보를 기반으로 사후 확률을 추론하는 통계적 방법인 베이즈 추정 기반 분류
- 종속변수 각 범주의 등장 빈도인 사전확률(prior) 설정이 중요
ex) "이전까지 이러이러한 빈도로 어떤 게 나왔다. 이 정도의 확률을 가진다" -> 사후확률 추론
- 각 데이터의 사전 확률을 기반으로 사후확률(posterior) 계산
from sklearn.naive_bayes import GaussianNBP( A|B ) = P(B|A) * P(A)
A : target, 종속변수
B : 독립변수
sklearn - GaussianNB()
- 나이브베이즈 분류 모델
- 독립, 종속변수는 fit() 에 할당
- model.class_prior_ : .value_counts( normalize = True) 결과 동일
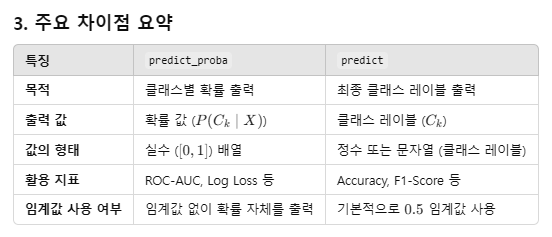
- predict_proba() : 예측 확률값
-> 임계치( threshold )가 0.5 라고 설정되어 있다면, predict_proba 를 사용할 필요는 없이 predict 를 사용해도 됨.
그러면, 성능지표를 바로 사용하기 편리함 (AUC 제외... AUC는 확률값이 필요하기때문에 predict_proba 결과값이 필요함)
# model.predict_proba 결과값
Predicted probabilities:
Proba =
[[9.99999996e-01 3.64569296e-09]
[9.99997000e-01 3.00025616e-06]
[1.17351869e-03 9.98826481e-01]
[6.14421235e-08 9.99999939e-01]]
# Proba 결과값을 임계치 0.5로 계산하면 아래 predict 결과값과 동일해진다
Proba_1 = ( Proba[ : , 1] > 0.5 ) + 0 #[0 0 1 1]
# model.predict 결과값
Predicted labels: [0 0 1 1]
- predict_proba를 사용할 수 있는 모델
- predict_proba는 클래스별 확률을 출력할 수 있는 모델에서 사용 가능합니다.
- 예제 모델:
- 로지스틱 회귀 (Logistic Regression) - 확률 기반 선형 모델.
- 랜덤 포레스트 (Random Forest) - 앙상블 학습 기반의 결정 트리 모델.
- 나이브 베이즈 (Naive Bayes) - 확률 기반 분류 모델.

- 이진/다중 분류의 경우, 출력된 예측 확률값의 두번째 열이 1이 될 확률
> chatGPT "GaussianNB 모델에서 왜 ' 출력된 예측 확률값의 두번째 열이 1이 될 확률' 이란 말을 하는 거야? "
예제
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 1. 데이터 준비
data = {
'Email Text': [
"Win a $1000 prize now",
"Meeting scheduled for 2 PM",
"Earn money fast and easy",
"Please review the attached file",
"Claim your free lottery ticket",
"Your invoice is attached"
],
'Label': ['Spam', 'Ham', 'Spam', 'Ham', 'Spam', 'Ham']
}
df = pd.DataFrame(data)
# 2. 데이터 전처리
# 레이블 숫자로 변환 (Spam = 1, Ham = 0)
df['Label'] = df['Label'].map({'Spam': 1, 'Ham': 0})
# 3. 텍스트 데이터를 벡터화 (Bag-of-Words)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['Email Text'])
y = df['Label']
# 4. 학습 및 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 5. 나이브 베이즈 모델 학습
model = MultinomialNB()
model.fit(X_train, y_train)
# 6. 예측
y_pred = model.predict(X_test)
# 7. 결과 평가
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
# 8. 새로운 이메일 예측
new_emails = ["Win a free vacation", "Project update meeting"]
new_emails_vectorized = vectorizer.transform(new_emails)
predictions = model.predict(new_emails_vectorized)
for email, label in zip(new_emails, predictions):
print(f"Email: '{email}' => {'Spam' if label == 1 else 'Ham'}")
> chatGPT :predict_proba 와 predic 차이는?"
- predict_proba는 클래스 0과 클래스 1의 확률 값을 모두 반환.
- predict는 기본적으로 확률 0.5를 기준으로 최종 클래스 레이블을 출력.
- Predict_proba 결과:
[[0.2, 0.8],
[0.6, 0.4],
[0.7, 0.3],
[0.1, 0.9],
[0.3, 0.7]]
Predict 결과: [1 0 0 1 ]


'Data Science > 실습' 카테고리의 다른 글
| DS 실습 18 - 의사결정나무 모델: 분류 및 회귀나무 (0) | 2024.12.08 |
|---|---|
| DS 실습 17- KNN(K-Nearest Neighbor) (0) | 2024.12.07 |
| DS 실습 15- 로지스틱 회귀분석 (0) | 2024.12.07 |
| DS 실습 13~14- 단순/다중 회귀분석 (0) | 2024.12.07 |
| 실기시험 준비 Python 기초 (3) | 2024.12.06 |